

This is a system design interview question, which is to design Spotify. In a real interview, usually, you would focus on one or two main functionalities of the app, but in this article, I would like to do a high-level overview of how you would design such a system, and then you can dive deeper into each separate part if needed.
Initial Phase: Base version
Requirements: The initial requirement for this is to handle 500k users and 30M songs. We will have users who play the songs and artists who upload the songs.
Estimation: Data math
Let’s start by estimating the storage that we need. First, we need to store the songs in some kind of storage.
- Song Storage: Spotify and similar services often use formats like Ogg Vorbis or AAC for streaming, and assuming an average song size is 3MB, we need 3MB * 30 million = 90TB of storage for songs.
- Song Metadata: We also need to store the song metadata and user profile information. The average metadata size per song is about 100 bytes — 100 bytes * 30 million = 3GB
- User Metadata: On average, we will store 1KB of data per user — 1KB * 500,000 = 0.5GB

High-Level Design
Mobile App: We will have a mobile app, which is the front end through which users interact with the service. Users can search for songs, play music, create playlists, etc. When a user performs an action (like playing a song), the app sends a request to the backend servers.
Load Balancer: But before reaching to servers we have a load balancer, which is to distribute incoming traffic across multiple web servers. This improves our application availability and fault tolerance.
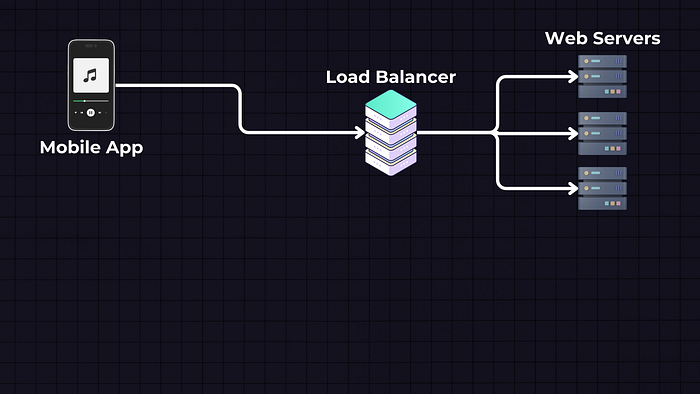
Web Servers (APIs): The web servers are the APIs that handle the incoming requests from the mobile app. For instance, if a user wants to play a song, the request is sent to these web servers. The server then determines where the song is located (in a database or a storage service) and how to retrieve it.
Data Storage
Data Storage will be split into two separate services — Blob Storage for Songs, where we will store the actual song files, and SQL Database, where we will store the song and user metadata.
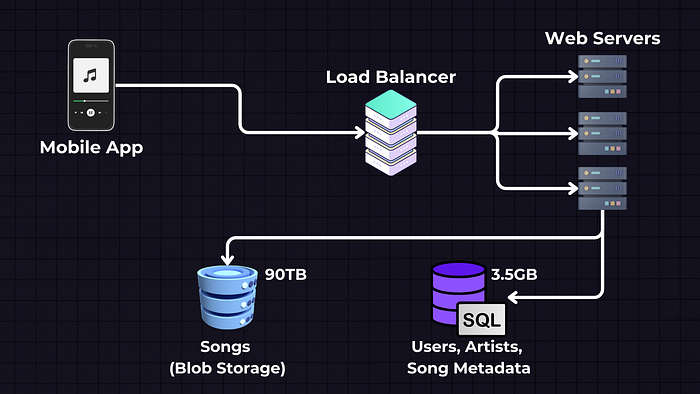
Songs — Blob Storage (e.g., AWS S3, GCP, Azure Blob Storage): The actual song files are stored in a Blob (Binary Large Object) storage service. These services are designed to store large amounts of unstructured data.
Users, Artists, and Song Metadata — SQL Database: This SQL database stores structured data such as user information (like usernames, passwords, and email addresses) and metadata about songs (like song names, artist names, album details, etc.).
Why SQL? SQL databases are ideal for this kind of structured data as they allow for complex queries and relationships between different types of data.
Each song file is stored as a ‘blob’, and the SQL database will typically store a reference to this file (like a URL)
SQL Database Structure
Here’s a basic outline of the tables and their relationships that we will have in our SQL database:
We will need a Users Table that contains the user metadata like UserID, Username, Email, PasswordHash, CreatedAt, LastLogin, etc.
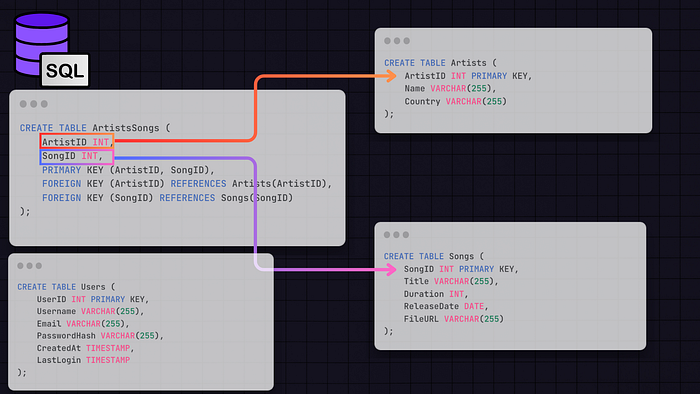
The Songs Table will hold the song metadata information, such as the SongID, Title, ArtistID, Duration, ReleaseDate, and FileURL, which is the URL to the location where the song file is stored (e.g., in a blob storage).
Artists Table will contain artist information — ArtistID, Name, Bio, Country, etc.
Relationships: We will join the Artists and Songs Tables in ArtistsSongs Table, where we will have the ArtistID (Foreign key pointing to the Artists Table) and SongID (Foreign key pointing to the Songs Table). From there, we can get the song metadata, which will also contain the FileURL property, pointing to the Blob storage where the song is located.
Putting it all together
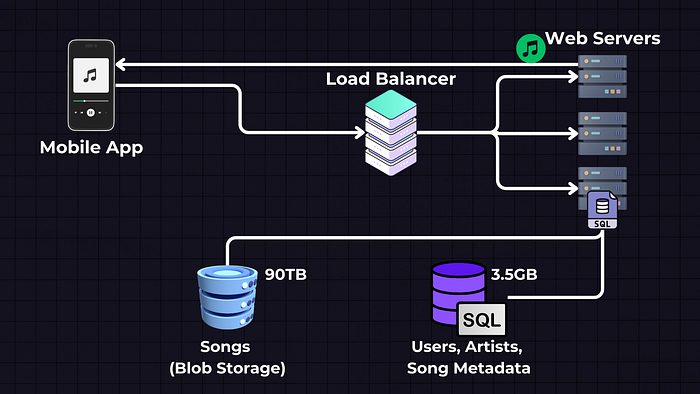
So, the web server will get the song metadata from the SQL database, and from the song metadata, it will get the fileURL, which will then be streamed from the server chunk by chunk to the mobile application. Or we can directly stream them from object storage to the client, bypassing the webserver to reduce load.
Scaled phase: 50M users, 200M songs
Now what if we scale to 50M users and 200M songs? We first need to recalculate the data. This means that the SQL data storage needs to store 200/30 = ~6.66 times more song metadata:
100 bytes per song * 200 million songs = 20GB
And the same goes for the user metadata:
1KB per user * 50 million users = 50GB

Introducing a CDN
Since the traffic has increased — we need to introduce caching and a CDN (like Cloudfront / Cloudflare) that will serve the songs, and each CDN will be geographically close to one region; therefore, it can serve the song faster than the web server.
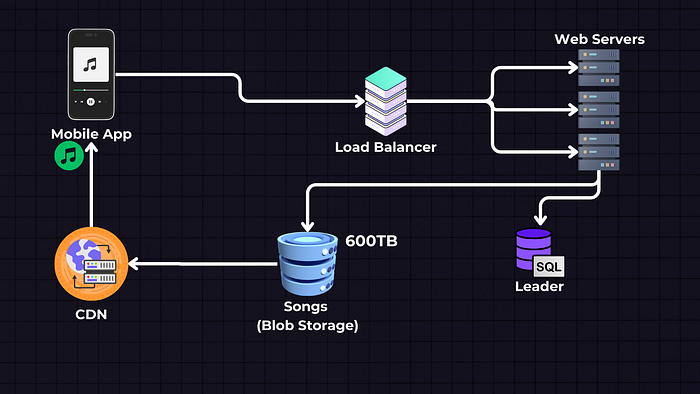
We can use an LRU (Least Recently Used) eviction policy for caching popular songs, and the unpopular songs will still be fetched from the Blob storage and then cached to the CDNs.
The song files can also be directly streamed from cloud storage to the client, which will reduce the load on web servers.
Scaling the Database: Leader-Follower Technique
The database also needs to expand. Since we know our app is getting a lot more Reads than Writes, meaning there are lots of users listening to songs but a relatively small amount of artists who upload songs — we can use the Leader → Follower technique and have one Leader database that will accept both Reads/Writes and multiple Follower or Slave databases that will be read-only for retrieving the song and user metadata.
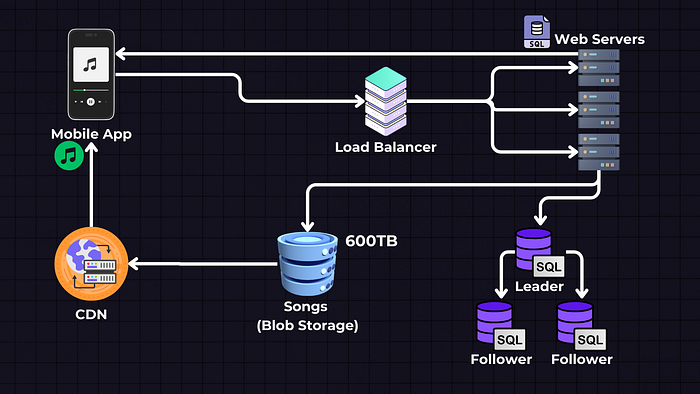
If necessary, we can also implement database sharding and split it to multiple SQL databases or implement a Leader ↔ Leader technique, but these are more complex scenarios, and you won’t encounter interviews where you’re asked too deeply about this.
If you’d like to learn more about each component that we discussed here, I have a detailed System Design Interview Concepts Tutorial where I go over each of them in more detail.
Link gốc: https://levelup.gitconnected.com/system-design-interview-question-design-spotify-4a8a79697dda
















 CỦA OBJECTIVE (MỤC TIÊU)")

{kind=link}